本书于2017-07由Packt Publishing出版,作者Giuseppe Bonaccorso,全书580页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Acquaint yourself with important elements of Machine LearningUnderstand the feature selection and feature engineering processAssess performance and error trade-offs for Linear RegressionBuild a data model zz~~ 7年前 (2017-08-27) 4626℃ 0评论14喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第二篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-08-16) 5568℃ 0评论6喜欢
我们在开发网站的时候一般都会分header、main、side、footer。这些模块分别包含了各自公用的信息,比如header一般都是本网站所有页面需要引入的模块,里面一般都是放置菜单等信息;而footer一般是放在网站所有页面的底部。当网页的内容比较多的时候,我们可以看到footer一般都是在页面的底部。但是,当页面的内容不足以填满一 w397090770 9年前 (2015-10-28) 4584℃ 0评论8喜欢
最近使用 Intellij IDEA 打开之前写的 HBase 工程代码,发现里面有个语法错误,但之前都没问题。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop后面发现,不管你使用的 JDK 是什么版本(我这里用的是 JDK 1.8),Intellij IDEA 设置的 Language Level 都是 1.5,如下:如果想及时了解Spark、Hadoop或者Hbase w397090770 6年前 (2018-07-12) 6058℃ 0评论4喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Best Practice in Accelerating Data Applications with Spark+Alluxio》的分享,作者来自 Alluxio 的 David Zhu。本次演讲将分享 Alluxio 和 Spark 集成解决方案的设计和用例,以及在设计和实现 Alluxio分 布式系统时的最佳实践以及不要做什么。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 3年前 (2021-10-28) 551℃ 0评论1喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章介绍了Spark的三大新特性,本文是Reynold Xin在2016年5月5日的演讲,视频可以到这里看:http://go.databricks.com/apache-spark-2.0-presented-by-databricks-co-founder-reynold-xinPPT下载地址见下面。 w397090770 8年前 (2016-05-24) 3267℃ 0评论4喜欢
Apache Pulsar(孵化器项目)是一个企业级的发布订阅(pub-sub)消息系统,最初由Yahoo开发,并于2016年底开源,现在是Apache软件基金会的一个孵化器项目。Pulsar在Yahoo的生产环境运行了三年多,助力Yahoo的主要应用,如Yahoo Mail、Yahoo Finance、Yahoo Sports、Flickr、Gemini广告平台和Yahoo分布式键值存储系统Sherpa。如果想及时了解Spark、Hadoop w397090770 7年前 (2018-01-16) 1991℃ 0评论9喜欢
Spark Release 1.0.2于2014年8月5日发布,Spark 1.0.2 is a maintenance release with bug fixes. This release is based on the branch-1.0 maintenance branch of Spark. We recommend all 1.0.x users to upgrade to this stable release. Contributions to this release came from 30 developers.如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopYou can download Spark 1.0.2 as w397090770 10年前 (2014-08-06) 5817℃ 2评论4喜欢
Apache Kafka 近期发布了 2.3.0 版本,主要的新特性如下:Kafka Connect REST API 已经有了一些改进。Kafka Connect 现在支持增量协同重新均衡(incremental cooperative rebalancing)Kafka Streams 现在支持内存会话存储和窗口存储;AdminClient 现在允许用户确定他们有权对主题执行哪些操作;broker 增加了一个新的启动时间指标;JMXTool现在可以连接到安 w397090770 5年前 (2019-06-27) 3053℃ 0评论6喜欢
在昨天我谈到了WSDL的一些概念,今天打算谈谈为什么理解WSDL非常重要。 许多用户可能会提到的一个问题是,既然WSDL文件可以在各种主要的平台上使用工具创建,为什么还要花时间学习WSDL呢?这是因为WSDL文档非常新,学习其内容和工作原理是明智的。由于Web服务正在变得无所不在,所以,理解和掌握WSDL文档的必要性越来 w397090770 12年前 (2013-04-25) 3098℃ 1评论2喜欢
在即将发布的 Apache Spark™ 3.2 版本中 pandas API 将会成为其中的一部分。Pandas 是一个强大、灵活的库,并已迅速发展成为标准的数据科学库之一。现在,pandas 的用户将能够在他们现有的 Spark 集群上利用 pandas API。几年前,我们启动了 Koalas 这个开源项目,它在 Spark 之上实现了 Pandas DataFrame API,并被数据科学家广泛采用。最近,Koala w397090770 3年前 (2021-10-13) 811℃ 0评论3喜欢
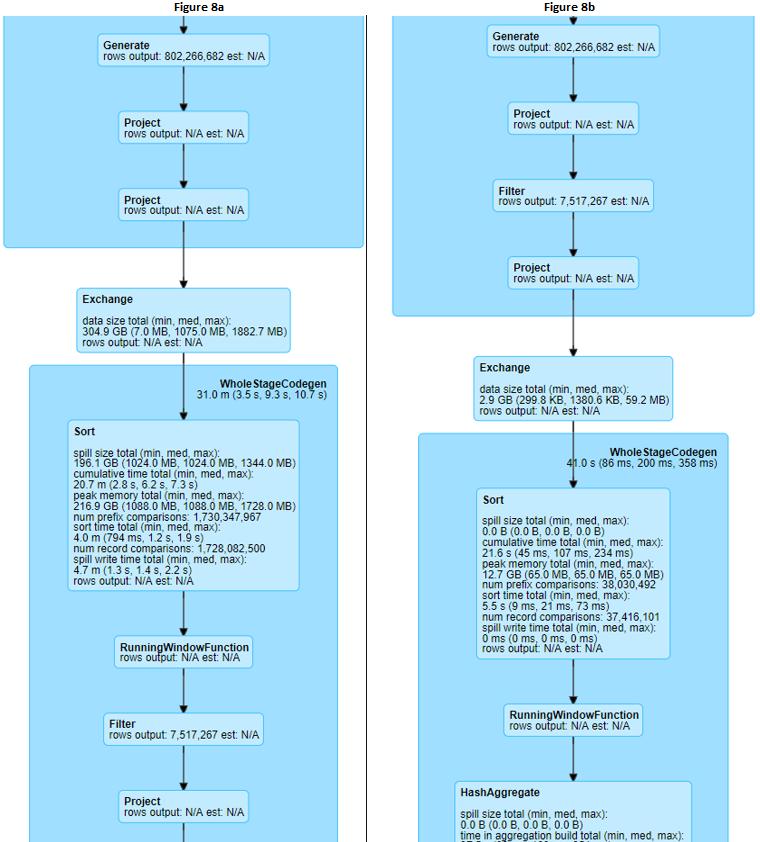
TPC-H是事务处理性能委员会( Transaction ProcessingPerformance Council )制定的基准程序之一,TPC- H 主要目的是评价特定查询的决策支持能力,该基准模拟了决策支持系统中的数据库操作,测试数据库系统复杂查询的响应时间,以每小时执行的查询数(TPC-H QphH@Siz)作为度量指标。我们在很多大数据系统上线或者产品上线的时候一般都会测 w397090770 3年前 (2021-10-29) 1603℃ 0评论5喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive提供三种可以改变环境 w397090770 11年前 (2013-12-24) 25303℃ 2评论10喜欢
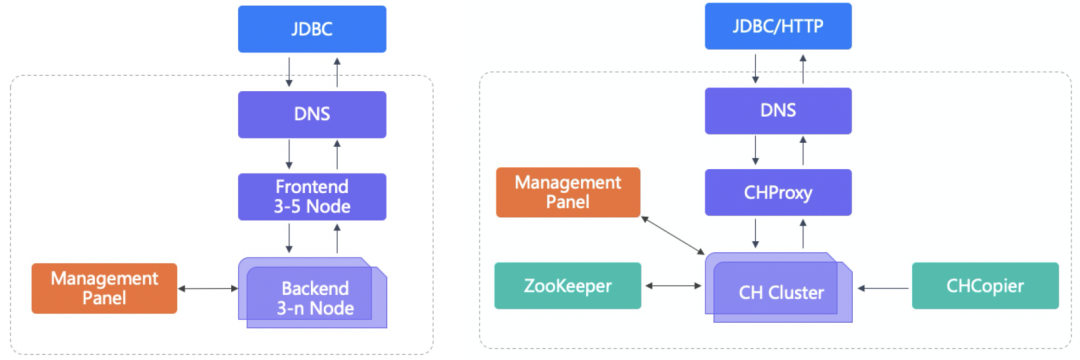
背景介绍Apache Doris是由百度贡献的开源MPP分析型数据库产品,亚秒级查询响应时间,支持实时数据分析;分布式架构简洁,易于运维,可以支持10PB以上的超大数据集;可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。 ClickHouse 是俄罗斯的搜索公司Yadex开源的MPP架构的分析引 w397090770 3年前 (2022-02-15) 2727℃ 0评论1喜欢
Wordpress的功能很强大,可以根据自己的需求来修改自己的网站。在Wordpress 3.5.1的中提供了默认的主题Twenty Twelve,很不错,但是首页显示的是全文信息,这不仅使得页面太长,也使得加载速度变的很慢,只有在搜索的时候才会显示摘要,那么怎么去让首页显示文章的摘要呢?到wordpress后台,依次选择 外观-->编辑-->选择右边的 w397090770 12年前 (2013-03-31) 27204℃ 9评论26喜欢
在本文中,我将分享一些关于如何编写可伸缩的 Apache Spark 代码的技巧。本文提供的示例代码实际上是基于我在现实世界中遇到的。因此,通过分享这些技巧,我希望能够帮助新手在不增加集群资源的情况下编写高性能 Spark 代码。背景我最近接手了一个 notebook ,它主要用来跟踪我们的 AB 测试结果,以评估我们的推荐引擎的性能 w397090770 5年前 (2019-11-26) 1575℃ 0评论4喜欢
上海Spark Meetup第四次聚会将于2015年7月18日在太库科技创业发展有限公司举办,详细地址上海市浦东新区金科路2889弄3号长泰广场 C座12层,太库。本次聚会由七牛和Intel联合举办。大会主题 1、hadoop/spark生态的落地实践 王团结(七牛)七牛云数据平台工程师。主要负责数据平台的设计研发工作。关注大数据处理,高 w397090770 9年前 (2015-08-26) 2896℃ 0评论3喜欢
WordPress 的自定义字段就是文章的meta 信息(元信息),利用这个功能,可以扩展文章的功能,是学习WordPress 插件开发和主题深度开发的必备。对自定义字段的操作主要有四种:添加、更新(修改)、删除、获取(值)。 1、首先自定义字段的添加函数,改函数可以为文章往数据库中添加一个字段:[code lang="php"]<?php add_ w397090770 10年前 (2015-04-30) 3527℃ 0评论8喜欢
由于Spark基于内存计算的特性,集群的任何资源都可以成为Spark程序的瓶颈:CPU,网络带宽,或者内存。通常,如果内存容得下数据,瓶颈会是网络带宽。不过有时你同样需要做些优化,例如将RDD以序列化到磁盘,来降低内存占用。这个教程会涵盖两个主要话题:数据序列化,它对网络性能尤其重要并可以减少内存使用,以及内存调优 w397090770 6年前 (2019-02-20) 3198℃ 0评论8喜欢
这篇文章是续着昨天的《Guava学习之SetMultimap》写的。AbstractSetMultimap是一个抽象类,主要是实现SetMultimap接口中的方法,但是其具体的实现都是调用了AbstractMapBasedMultimap类中的相应实现,只是将AbstractMapBasedMultimap类中返回类行为Collection的修改为Set。下面主要说说AbstractSetMultimap类的相关实现。 1、在AbstractMapBasedMultimap类中就 w397090770 11年前 (2013-09-26) 2858℃ 1评论5喜欢
最近修改了Spark的一些代码,然后编译Spark出现了以下的异常信息:[code lang="scala"]error file=/iteblog/spark-1.3.1/streaming/src/main/scala/org/apache/spark/streaming/StreamingContext.scalamessage=File line length exceeds 100 characters line=279error file=/iteblog/spark-1.3.1/streaming/src/main/scala/org/apache/spark/streaming/StreamingContext.scalamessage=File line length exceeds 100 characters w397090770 9年前 (2015-05-20) 6016℃ 0评论3喜欢
Apache Spark 和 Apache HBase 是两个使用比较广泛的大数据组件。很多场景需要使用 Spark 分析/查询 HBase 中的数据,而目前 Spark 内置是支持很多数据源的,其中就包括了 HBase,但是内置的读取数据源还是使用了 TableInputFormat 来读取 HBase 中的数据。这个 TableInputFormat 有一些缺点:一个 Task 里面只能启动一个 Scan 去 HBase 中读取数据;TableIn w397090770 6年前 (2019-04-02) 13073℃ 5评论18喜欢
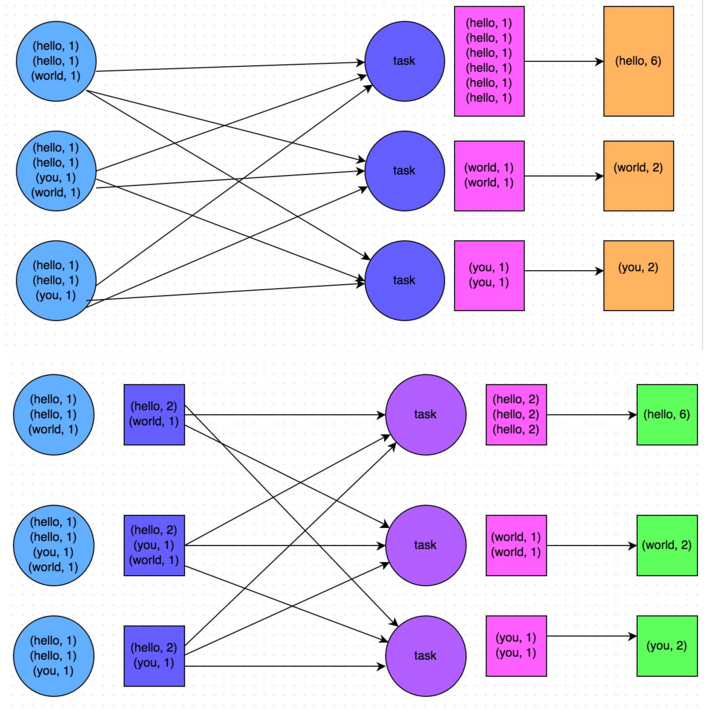
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计 w397090770 9年前 (2016-05-04) 16820℃ 3评论45喜欢
本书作者 Denny Lee, Tathagata Das, Vini Jaiswal,预计2022年4月出版,出版社 O'Reilly Media, Inc.,ISBN:9781098104528分析和机器学习模型的好坏取决于它们所依赖的数据。查询处理过的数据并从中获得见解需要一个健壮的数据管道——以及一个有效的存储解决方案,以确保数据质量、数据完整性和性能。本指南向您介绍 Delta Lake,这是一种开 w397090770 3年前 (2021-05-27) 570℃ 0评论2喜欢
在前面的《Guava学习之Multimap》文章中我们谈到了Guava类库中的Multimap,其特点是存在在Multimap中的键值对可以不唯一;而我们又知道,在Java集合类库中有个Map,它的特点是存放的键(Key)是唯一的,而值(Value)可以不唯一,如果我们需要键(Key)和值(Value)都唯一,该怎么实现?这就是今天要谈的BiMap结构。 在过去,如 w397090770 11年前 (2013-07-10) 7176℃ 2评论2喜欢
本文转载至 http://www.ibm.com/developerworks/cn/java/j-dcl.html 单例创建模式是一个通用的编程习语。和多线程一起使用时,必需使用某种类型的同步。在努力创建更有效的代码时,Java 程序员们创建了双重检查锁定习语,将其和单例创建模式一起使用,从而限制同步代码量。然而,由于一些不太常见的 Java 内存模型细节的原因,并不能 w397090770 11年前 (2013-10-18) 4653℃ 4评论6喜欢
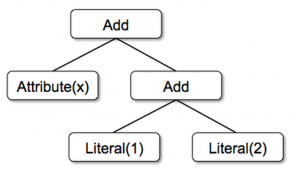
Spark SQL 是 Spark 最新且技术最复杂的组件之一。它同时支持 SQL 查询和新的 DataFrame API。Spark SQL 的核心是 Catalyst 优化器,它以一种全新的方式利用高级语言的特性(例如:Scala 的模式匹配和 Quasiquotes ①)构建一个可扩展的查询优化器。最近我们在 SIGMOD 2015 发表了一篇论文(合作者:Davies Liu,Joseph K. Bradley,Xiangrui Meng,Tomer Kaftan w397090770 5年前 (2019-07-21) 3256℃ 0评论5喜欢
Apache Spark 2.1.0是 2.x 版本线的第二个发行版。此发行版在为Structured Streaming进入生产环境做出了重大突破,Structured Streaming现在支持了event time watermarks了,并且支持Kafka 0.10。此外,此版本更侧重于可用性,稳定性和优雅(polish),并解决了1200多个tickets。以下是本版本的更新:Core and Spark SQL Spark官方发布新版本时,一般 w397090770 8年前 (2016-12-30) 4239℃ 0评论8喜欢
Facebook Spark 的使用情况在介绍下面文章之前我们来看看 Facebook 的 Spark 使用情况:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopSpark 是 Facebook 内部最大的 SQL 查询引擎(按 CPU 使用率计算)在存储计算分 w397090770 4年前 (2020-06-14) 1556℃ 0评论6喜欢
我在《使用Hive读取ElasticSearch中的数据》文章中介绍了如何使用Hive读取ElasticSearch中的数据,本文将接着上文继续介绍如何使用Hive将数据写入到ElasticSearch中。在使用前同样需要加入 elasticsearch-hadoop-2.3.4.jar 依赖,具体请参见前文介绍。我们先在Hive里面建个名为iteblog的表,如下:[code lang="sql"]CREATE EXTERNAL TABLE iteblog ( id b w397090770 8年前 (2016-11-07) 19951℃ 1评论24喜欢